

Designing a Declarative Data Stack: From Theory to Practice


This is Part 3 of a 3 part blog series guest written by Simon Späti . See Part 1: The Rise of the Declarative Data Stack, and Part 2: BI-as-code and GenBI.
What started as a straightforward implementation guide for a declarative data stack quickly evolved into something more fundamental. While attempting to build a system that could define an entire data stack through a single YAML file, I encountered architectural questions that challenged my initial assumptions:
- Should we generate production-ready code from templates or create a boilerplate repository with best-in-class tools?
- Should we leverage existing orchestration tools that already integrate with the data lifecycle or build something new?
- Should we use Kubernetes/Docker as a compute engine?
These questions touch on core architectural decisions that any declarative data stack must address. In exploring my initial proof-of-concept for the declarative-data-stack-engine, I discovered that choosing between a template engine versus a starter kit or between custom infrastructure versus existing orchestration tools influences how we build and maintain data stacks at scale.
This article chronicles that journey, examining the key architectural considerations and trade-offs in building a declarative data stack and its engine or factory. We'll explore and compare different implementation strategies, all while focusing on creating a data stack that separates out business logic in a maintainable way.
How the Declarative Data Stack Transforms Data Engineering
A quick reminder: Why do we use a declarative data stack as introduced in Part 1? It allows us to automate the entire data stack, focusing on the business logic, not technical implementation. Tools that lack these declarative code paths are difficult to automate, because code generation is almost impossible (imagine trying to auto-generate Tableau dashboards or Informatica pipelines). By applying software engineering best practices we can build complete "data stack compilers" that run tests before being put into production, and build versioned, maintainable, and reproducible data stacks.
A declarative data stack enables less technical users, can handle more significant complexity, has built-in data governance, and works well for large organizations. Essentially, designing a compiler/makefile for the data stack declared from a single function or config file.
When do you know you would profit from one? Usually, it starts with these questions that we, data engineers, have asked ourselves:
- What if we could generate the declarative code for an entire data pipeline with just a few lines of config?
- How can we truly separate our business logic from the technical implementation?
- Could we test the entire data stack locally before pushing it to production?
- Could we annotate our table types – staging, slowly-changing dimension tables, fact tables – in a single config/annotation?
- What if you could easily "shift left" logic by changing parameters in a config file, such as aggregating at ingestion (versus at query time)?
- What if we could declare every piece in our data stack using a single consistent language, such as SQL?
These questions represent core challenges that drive the design of modern data stacks. Each question addresses a critical pain point in data engineering, and together, they point towards a compelling vision: a fully declarative approach could change how we design data stacks.
In this article, we will start with a simple example, then move on to one that utilizes basic templates, and finally evolve towards generating a data stack with a data orchestrator. Then, we will address some of the questions raised above.
Understanding the Core Components
When implementing a system that can generate a declarative data stack (DDS), I immediately hit the first critical question: "Do we build just a code-generating factory for the data stack? Or do we build a system that also deploys the data stack and runs its services?" To answer this, we must lay out the different parts of a declarative data stack and potential declarative data stack engine or factory (DDSE).
I discovered that our stack consists of three main parts, and depending on what we want to solve, we must decide where to start.
Architectural Components
To better understand, let's look at the overall architecture and the three parts are the following:
- Config: Defines the stack and project-related configs, typically YAML.
- Engine: This is akin to a compiler that takes as inputs defined configs and generates outputs of declarative code artifacts for the chosen tools in our data projects. Think of it as a factory that produces a declarative data stack—and it may also run the data stack it generates, depending on the implementation extent.
- Declarative code: The code generated by the engine, which often takes the form of a Git-managed repository and in one or many YAML files.
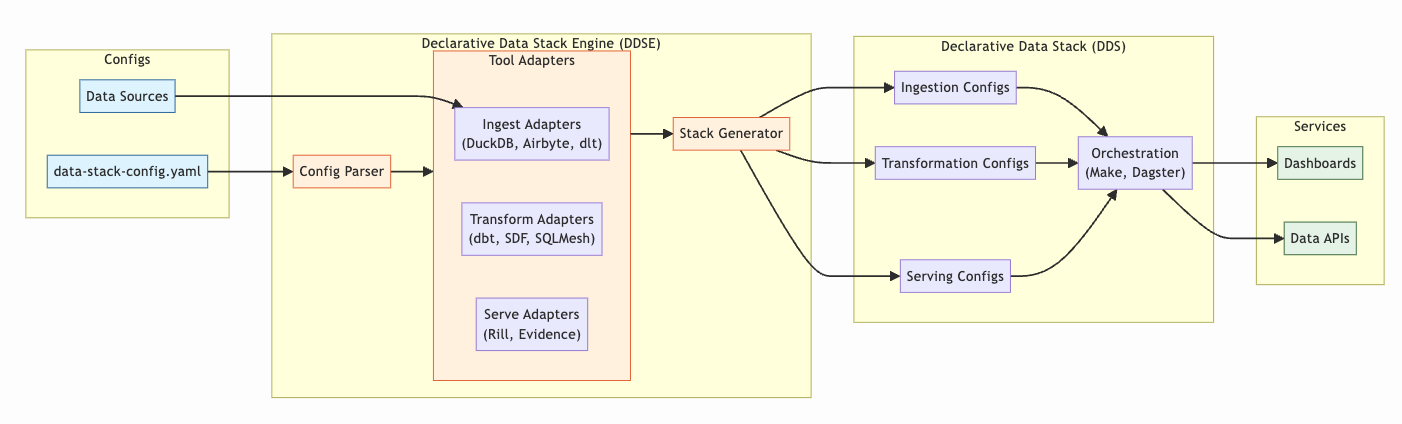
Starting with a declarative configuration, we define actual data sources (with credentials), transformations, and APIs and dashboard services. Next, we have an engine which reads these configs and generates the declarative code for a working data stack. We can iterate on this in our development environment and eventually deploy it to production.
DDSE: Is it an "Engine" or a "Factory"
The DDSE can be seen as the factory that converts the configs to the declarative data stack. But also, depending on the features, e.g., running the declarative data stack, the word engine might also be appropriate. In this article, I decided to use the engine as the main word as it fits better to hold both use cases, but when it made sense, the factory was used too.
Generated Data Stack vs. Engine: Key Distinctions
Let's clarify: there is the "data stack" (DDS) and the declarative data stack "engine" (DDSE). These are two distinct concepts that are important to distinguish. One focuses on specific projects, while the other focuses on ergonomics, generating, and developing the stack.
For example, the declarative data stack holds the ingestion source locations, transformations, dashboards, and the business logic of a company. Conversely, the engine is the infrastructure supporting data engineers to build the end stack along the data flow and lifecycle and potentially run it. This is a crucial differentiation; let's compare them in more detail to know what we need to build. The below table gives us a better understanding:
Remember the declarative example from Part 1 with the configuration (text) and engine/factory (Google Docs, HackMD, GitHub): Markdown. Our text is the configuration, and to present it either in your local text editor, a web UI or on your website, you have three different engines that convert it to the correct format.
Implementation of a Declarative Data Stack Engine
Let's make it more concrete and look at some code.
I created a simple example to showcase the difference between (imperative) Python code with all the configs built-in vs. a more declarative approach with templates, where we extract all business logic into a YAML config.
Later, we see an example where we use Dagster, which uses a declarative orchestrator to build our DDS engine.
Simple vs. Templated Data Stack Example
Below, we have two examples, a TemplateDataStack() and a SimpleDataStack(); we look at the implementation code and the difference between what a declarative data stack with a simple config file brings to the table.
The Templated-Driven Data Stack
So, what would we need to implement for such a DDSE? What does the architecture look like, and what components do we need? What config needs to be written?
We'll start with the templated data stack. Below we see the configuration file [1] that defines the full data stack from ingestion to serving. Not only can this config be consumed by the declarative data stack, but even external services (e.g., GDPR checks or integrations with SAP, etc.) could potentially read and integrate that too (full code in 1-simple-stack.py).
sources:
- table: raw_sales
transformations:
- output_table: sales_daily
source_table: raw_sales
group_by:
- "date_trunc('day', sale_date)"
metrics:
- name: daily_sales
column: amount
agg: SUM
- name: transaction_count
column: '*'
agg: COUNT
dashboard:
title: Sales Analytics
output_path: dashboards/sales_dashboard.yaml
visualizations:
- title: Daily Sales Trend
type: line
query: SELECT * FROM sales_daily ORDER BY sale_date
- title: Transaction Volume
type: bar
query: SELECT sale_date, transaction_count FROM sales_dailyYou see, the configuration is simple to understand, and the business logic, like transformation, metrics, or dashboards, is in one place. We can even use abstractions such as referencing the logical name sales_daily in our dashboard that's generated in transformation.
This helps to separate concerns and distinguish between business and technical logic. The source, the transformation, is what we want to achieve, whereas the code below implements the "how", and directly executes it. The Python code for this simple example - consuming this file, building, and running the declarative stack looks - like this:
class TemplateDataStack:
def __init__(self, config_path: str):
self.conn = duckdb.connect(':memory:') # Use in-memory database
self.config = self._load_config(config_path)
def _load_config(self, config_path: str) -> dict:
with open(config_path) as f:
return yaml.safe_load(f)
def _create_sample_data(self):
[...]
return sales_data
def ingest(self):
sales_data = self._create_sample_data()
for source in self.config['sources']:
table_name = source['table']
# Load sample data directly into table
self.conn.execute(f"CREATE TABLE {table_name} AS SELECT * FROM sales_data")
print(f"Created and populated table: {table_name}")
def transform(self):
for transform in self.config['transformations']:
table_name = transform['output_table']
group_by = transform.get('group_by', [])
metrics = transform['metrics']
source_table = transform['source_table']
# Build dynamic query
select_parts = []
for col in group_by:
select_parts.append(col)
for metric in metrics:
select_parts.append(f"{metric['agg']}({metric['column']}) as {metric['name']}")
query = f"""
CREATE OR REPLACE TABLE {table_name} AS
SELECT {', '.join(select_parts)}
FROM {source_table}
{f"GROUP BY {', '.join(str(i+1) for i in range(len(group_by)))}" if group_by else ''}
ORDER BY {group_by[0] if group_by else '1'}
"""
self.conn.execute(query)
print(f"Created transformed table: {table_name}")
# Display sample results
result = self.conn.execute(f"SELECT * FROM {table_name} LIMIT 5").fetchdf()
print(f"\nSample results from {table_name}:")
print(result)
def serve(self):
dashboard_config = {
'title': self.config['dashboard']['title'],
'charts': []
}
for viz in self.config['dashboard']['visualizations']:
dashboard_config['charts'].append({
'name': viz['title'],
'query': viz['query'],
'type': viz['type']
})
[...]
print(f"Created dashboard configuration at {output_path}")Still, many details have been left out, but it gives us a good base for comparing it to a stack that doesn't use declarative configuration.
The Simple Data Stack
Comparing it to a simpler, but imperative data stack (full code in 1-simple-stack.py), with no configuration file, it looks like this:
class SimpleDataStack:
def __init__(self):
self.conn = duckdb.connect(':memory:') # Use in-memory database for simplicity
def _create_sample_data(self):
[...]
return sales_data
def ingest(self):
# Create sample data and load it directly
sales_data = self._create_sample_data()
self.conn.execute("CREATE TABLE raw_sales AS SELECT * FROM sales_data")
print("Ingested sample sales data")
def transform(self):
self.conn.execute("""
CREATE OR REPLACE TABLE sales_daily AS
SELECT
date_trunc('day', sale_date) as sale_date,
SUM(amount) as daily_sales,
COUNT(*) as transaction_count
FROM raw_sales
GROUP BY 1
ORDER BY 1
""")
print("Transformed data into daily sales aggregates")
def serve(self):
dashboard_config = {
'title': 'Sales Dashboard',
'charts': [{
'name': 'Daily Sales',
'query': 'SELECT * FROM sales_daily ORDER BY sale_date'
}]
}
[...]
print("Created dashboard configuration")
# Display sample results
result = self.conn.execute("SELECT * FROM sales_daily LIMIT 5").fetchdf()
print("\nSample results:")
print(result)You see, the business logic and technical logic are all mixed up. It's harder to read already with this simple example, but the more significant our project, the more unreadable such imperative code gets.
Running the Declarative Data Stack
We can see one key difference in how to run the SimpleDataStack() and TemplateDataStack().
Imperative code with config inside the code:
stack = SimpleDataStack()
stack.ingest()
stack.transform()
stack.serve()Example with declarative config:
stack = TemplateDataStack('stack_config.yaml')
stack.ingest()
stack.transform()
stack.serve()If we run this particular example, the Python script with the two examples, the output looks like below:
python 1-simple-stack.py
=== Running Constant Stack ===
Ingested sample sales data
Transformed data into daily sales aggregates
Created dashboard configuration
Sample results:
sale_date daily_sales transaction_count
0 2024-01-01 6291.0 24
1 2024-01-02 7356.0 24
2 2024-01-03 7135.0 24
3 2024-01-04 6716.0 24
4 2024-01-05 6121.0 24
=== Running Template Stack ===
Created config file at config/stack_config.yaml
Created and populated table: raw_sales
Created transformed table: sales_daily
Sample results from sales_daily:
date_trunc('day', sale_date) daily_sales transaction_count
0 2024-01-01 5480.0 24
1 2024-01-02 7271.0 24
2 2024-01-03 6600.0 24
3 2024-01-04 6593.0 24
4 2024-01-05 6385.0 24
Created dashboard configuration at dashboards/sales_dashboard.yamlThe logs are the same, but the implementation differs. Notice in this example that the Python script executes the declarative data stack, not only generating the stack_config.yaml and dashboards yaml.
In conclusion, the two approaches are similar. However, the key difference of the simple data stack is that it combines business logic with implementation logic and, therefore, cannot be reused or separated from the configurations.
Design Patterns and Architecture
Let's compare these two approaches, highlighting their pros and cons, and contrast them with other popular methods in the data space before checking how they would look when implemented with a declarative data orchestrator.
Lessons from Data Warehouse Automation
A quick throwback nearly 10 years ago: I used data warehouse automation (DWA) tools very similar to what we are trying to achieve here. At that time, we designed and defined the entire data warehouse within the DWA tool (our DDSE) and generated it from templates and configs. The output was generated SQL (tables, queries to create, business logic - our DDS) or stored procedures (compute, runtime - the DDS engine) that were ready to deploy to dev or production. And if you change or fix it, you'd never fix the generated code; fix the template and regenerate it.
I won't go into all the details of data warehouse automation in this article, as many excellent tools are still available (see more in the callout below). Nonetheless, it's worth mentioning for comparison, as the model was one of the most efficient ways to build data warehouses with outstanding ergonomics.
Why, you ask? If a customer wanted to add a new data source or change requirements (which happens constantly), we could create a full-blown data warehouse instead of engaging in lengthy discussions about theoretical data models and design. It had all the artifacts with a runner, ingesting the sources (generated from the source table information schema); the data was modeled in star and dimension schema; we could add SCD2 with one click as there was a template, and data marts were generated.
It could be deployed locally, on a server, or in production instantly. We could demonstrate and discuss based on an actual prototype and, in some cases, directly fix or change it during the workshop or meeting.
I believe a DDS should be built at the same velocity using a generic DDS engine and factory.
Quick History of Data Warehouse Automation Tools (DWA)
Data Warehouse Automation (DWA) emerged as businesses required faster data-driven decisions and could no longer wait months for traditional warehouse implementations. Early DWA tools focused on two distinct approaches: model-driven (design first, data later) and data-driven (starting with available data, iterating on design). The latter proved more suitable for agile methodologies.
By 2015-2017, tools like WhereScape, TimeXtender, and BiGenius (now called BiGenius-X) dominated the market, offering features from automated ETL generation to complete lifecycle management. What made DWA revolutionary wasn't just the automation but the shift in how teams worked with data. Instead of spending months on specifications, teams could prototype in days, test with actual data, and iterate based on business feedback. This fundamentally changed the dynamics of data warehouse projects, much like how we're seeing similar patterns emerge in modern data stack engineering. Read more on Data Warehouse Automation (DWA) – Series
Parametric vs Template-Based Data Pipelines
Another related term, "parametric data pipeline" was released recently. Maxime Beauchemin brought that up in his great piece. He defines parametric as:
The term "parametric" refers to the pipeline's ability to adapt to various configurations and customizations through parameters, thereby adapting the underlying logic.
He raises the same questions we discovered, specifically the debate between parametric and template-oriented approaches: When to use configurations versus when to use templates? Max says a purely parametric approach can create a complex black box that is hard to modify. On the other hand, a template-oriented approach means that once you fork, you are primarily on your own. The best solution might be a blend of both: a solid foundation with parametric capabilities while allowing for forking when needed.
Although this example focuses only on the data transformation layer of the entire data stack, it still highlights the question of parametric versus template-driven approaches. It's also essential to set constraints; with a declarative data stack, we mainly focus on tools to integrate locally first to compile and test before deploying to production, potentially a singular machine to avoid distributed engines, which would lead to a more complex system.
Maintaining the Declarative Flow
It's essential to distinguish between declarative systems and merely a declarative wrapper. For example, a tool like dbt is a declarative wrapper around SQL, not a truly declarative interface. By adding another layer on top, we introduce yet another interface.
Everything a developer interacts with should be declarative, including infrastructure, runtime, type evolution, CDC logic, credentials, and schedules. Non-declarative elements should be compartmentalized with declarative interfaces. Remember, we developers shouldn't make imperative decisions about scope and execution; the engine should handle that.
Building a Modular Engine
It's now more apparent to me that the declarative data stack would benefit from an engine that helps us build the entire stack without reimplementing everything, but rather by navigating through the integration of a vast complex data landscape, creating an open-source, homogeneous, and generated data stack.
As with such an engine approach, we support the entire lifecycle and are automated. Also, with compilers and generators, as you constantly generate, your code gets better, and you get more confident to deploy as you have been doing that continually. One key seems to have a strong SQL query execution framework; that's why many existing tools run on Apache Datafusion, DuckDB, or SQLGlot.
The other big reason, and should be more clear by reading Part 2, BI-as-Code and the New Era of GenBI is that declaration and, therefore, the context of the complete end-to-end analytics solutions is crucial if you want to add any natural language or AI-powered (copilot, semantic understanding, generation, etc.) features on top. Opening up data for everyone, not only for engineers, with the support of AI.
Data Modeling Architecture
So, where do you significantly define the layers and the data model architecture? This can and does vary in each project, depending on the requirements.
Good question. This belongs to the actual project, therefore, in the configurations of the DDS (and not the engine). More specifically, its implementation logic, even business logic, which the function transform() needs to handle. If it's dbt, SDF, or SQLMesh, which all do very well, it doesn't matter for the declaring data stack definition. Each engine needs to generate it correctly for each transform adapter.
The DDS is what we want to implement. The DDSE is only the how, which tools, and the technical part.
How Is It Different from an Orchestrator?
While building and brainstorming on top of existing stacks, especially when avoiding creating an imperative wrapper around a declarative approach, I asked myself, why not use a declarative orchestrator (Kestra, Dasgster, etc.)?
Can I get a better separation of concerns with the advanced out-of-the-box features? For example, Dagster already supports many features, such as separating business logic in asset functions, executing infrastructure with various compute integrations, and having technical implementation abstracted elegantly through resources.
Many modern orchestrators already position themselves as data platforms. They integrate various tools and typically run on Kubernetes to spawn containers for data pipelines, exemplifying this convergence between orchestration and comprehensive data platforms.
The key distinction lies in how these systems handle tool integration. While orchestrators typically provide libraries to integrate different tools, the DDSE approach focuses on implementing specific adapters for each tool. However, orchestration tools also usually support YAML-based DSLs (Domain Specific Languages) to define pipelines or with annotations, as seen below, and both handle the transformation of these declarations into executable workflows. However, orchestration focuses solely on pipelines and assets, whereas a DDSE typically integrates all data stack tools.
The main difference might be that closed-source orchestrators often integrate tightly with specific databases or SQL dialects, whereas a DDSE aims to be more open and adaptable.
This leads to practical implementation questions: Should the factory and engine be built in Python/Rust to handle config conversion and tool integration, or should it function more like an orchestration layer that consumes downstream configs? The DWA (Data Warehouse Automation) approach suggests working purely with templates and configs, never touching the scaffolded code. This aligns with modern orchestrators' parametric approach, where configurations drive the system's behavior through a clean DSL interface supported by robust SQL query engines like DuckDB or Datafusion.
The ultimate question becomes whether to pursue an all-in-one engine or focus on providing a simple startup framework. The DDSE concept should take inspiration from orchestrators but emphasize generating and maintaining consistent implementations across tools through its adapter system. When users fix an issue, they improve the engine's templates rather than modifying generated code, benefiting all future deployments.
This would suggest that while a DDSE shares many characteristics with orchestrators, it serves a distinct purpose in standardizing and automating the creation and maintenance of data stacks. Another way to build something is to integrate a higher-level abstraction closer to the paradigm and approach of DWA tools.
Ultimately, the orchestrator might be the one way to create a DDS engine. A Rust-based engine is implemented as a second way.
The Dagster Data Stack Example
After the two code examples (simple and template data stack) above, I tried to write a pseudo-code to see what it looks like with a declarative orchestrator, especially with Dagster.
The key is that we can use annotations on top of Python, which gives us the super-power of a declarative way but with the functionality of Python to write code. We can implement the technical implementation logic with Python in a general way. We can define parametric configurations as annotations directly within our pipeline while still being able to use YAML files to conveniently consume.
For example, the asset for the ingestion (full code in 4-dagster-stack.py):
@asset(
auto_materialize_policy=AutoMaterializePolicy.eager(),
partitions_def=daily_partitions,
metadata={
"table": "raw_sales",
"schema": "public",
"description": "Raw sales data from source system"
}
)
def raw_sales(context) -> Output[pd.DataFrame]:It is interesting that most of the code will fall back to its description as most of the boilerplate and technical implementation is handled by Dagster. And anything we want to add, we should pack into reusable, technical resources that, for example, Dagster offers.
This example could be explored in much more detail, but as this article is already way long, I will leave this for another time. Please also reach out if you have thoughts or implemented something related.
Two more Data Stack Iterations: Making it Truly Declarative
I also prompt engineered two more data stacks to illustrate it even more - Check them out on GitHub, linked below for full details:
- 2-stack-update.py: Using StateManager(), DependencyGraph() and TestManager() to manage more of the data stack
- 3-stack-truly-declarative.py: Abstracting every detail of the stack and creating objects for DataType(), ChartType() and Column(), Schema() and DataSource() but also for Transformation(), Metric(), Dashboard(), ServingLayer() and Pipeline() with overall DeclarativeEngine()
Are we Building a DSL (Domain Specific Language) only?
There is a fine line between programming the thing, declaring it, and adding a DSL (Domain Specific Language). Usually, you end up at a DSL if you want to involve less technical people. But then you have the tradeoff that you can only do some things by declaring and only what you have implemented the transpiler to understand.
An interesting new language called Cue Lang, an improved version of YAML, can be used programmatically. CUE makes it easy to validate data, write schemas, and ensure that configurations align with policies.
Existing DDS Factories or Engines and Tools
During my exploration, I discovered existing tools that achieve similar objectives. Let's take a look at what they do and if they share the same goal in mind.
Curated List of Open Data Stacks Projects
Many of you may have implemented various data stacks. I have, too. Find many examples in this curated list.
Close-Sourced DDSEs
Let's start with closed-source first—one key point to note. Most of what we've discussed here is something that most closed-source tools have implemented in one way or another. Because they've built one big monolith, this is relatively straightforward and the natural thing to do.
This can be more challenging and not immediately obvious with an open-source approach and numerous integration tools. Let's now look at tools that have successfully implemented such features.
- Ascend: The platform automates up to 90% of repetitive data tasks using their DataAware Automation Engine.
- Palantir Foundry: One of the first lakehouse implementations before the term was coined. Enables real-time collaboration between data, analytics, and operational teams through a common logic data lake layer
- Find more on Closed-Source Data Platforms and a fantastic read on composable data stacks on a new frontier by Voltron Data.
Usually, the problem with closed-source software is that it is structured as a monolith, combining transformation logic with persisted database tables while keeping the underlying code unknown.
Open-Source DDSEs
But even more interesting are the open-source tools I found [2] - they are fantastic and built in the open, building in the open. Not all might be truly declarative data stacks by their definition, but they all build on top of other tools and declaratively integrate them.
- DataForge: Write functional transformation pipelines by leveraging software engineering principles. It does not have a visualization tool that focuses on transformation [3].
- Dashtool: A Lakehouse build tool that builds Iceberg tables from declarative SQL statements and generates Kubernetes workflows to keep these tables up-to-date. It handles Ingestion, Transformation, and Orchestration. Written in Rust and uses Datafusion.
- BoilingData: A local-first data processing native application designed for rapid data pipeline development. Enables data engineers to build and test pipelines quickly using tools like DuckDB, dbt, and dlt.
- HelloDATA: An enterprise data platform built on open-source tools based on the modern data stack. It uses state-of-the-art tools such as dbt for data modeling with SQL and Airflow to run and orchestrate tasks, Superset to visualize the BI dashboards, and JupyterHub for data science tasks. It includes multi-tenancy, full authentication, and authorization, which are handled with a single web portal.
- SDF: Similar to DataForge, built on Rust and Datafusion. Tries to be the Typescript for SQL, creating faster development cycles and reliable results with a powerful compiler.
- SQLMesh: An efficient data transformation and modeling framework that has compiler capabilities built-in with SQLGlot, a Python SQL parser and a transpiler.
- GitHub Actions: This is the simplest version for building a declarative data stack. A
deploy.yamlscript could be a simple DDS config. GitHub also has an engine that converts and runs on Docker-runners. So, in a way, it's another engine implementation, and maybe we could take some configs based on that? - Datacoves: The platform helps enterprises solve data analytics challenges with managed dbt, Airflow, and VS Code, adopting best practices. This approach avoids negotiating multiple SaaS contracts and reduces consulting costs without compromising data security.
- Datadex: Serverless and local-first Open Data Platform.
- BigFunctions: A framework to build a governed catalog of powerful BigQuery functions, SQL first approach. Ingesting, advanced data transforms, and serving data on a data app with a single SQL query.
SQL Compilers
SQLGlot would be a good integration to parse SQL without running. Same as SDF integration with Datafusion.
Existing Templating
Beyond tools, templating can solve some of the Jinja Template, GoLang's template package, biGENIUS Template modules, Apache Velocity, Liquid, and many others.
The Role of Open Standards
Lastly, before we conclude this exploratory article, let's examine some relevant concepts I came across. The roles of standardization and data engineers, such as functional data engineering and open standards, are noteworthy. Let's review how open standards can facilitate tool interoperability and unify the open-source declarative data stack.
Functional Data Engineering
With the concept of functional programming, we aim to separate transformation logic from the state, thereby enabling the recreation of the state when running a pipeline with the same input parameters and incoming data, fulfilling the promise of idempotency.
As outlined in detail in Part 1, the declarative data stack cleanly separates semantics from implementation, decoupling the business code from technical implementation.
Separating Data Engineering and Business Roles
Amid all this exploration, we must consider the roles of data engineers and the business. As with the DDSE, we focus on the developer ergonomics of data engineers, not business users.
Depending on how we set the line, we're also defining roles. For example, data would be self-sufficient and self-serve in a perfect world. This means a business user who does not know anything about dbt, SDF, Rill, or anything would want to create a config (maybe with a nice UI), and then the data engineer would handle the rest. This could also be the distinction between the DDS (the business user/analyst) and the DDSE (engineer), which implements the technical part.
If a dbt pipeline fails, the data engineer fixes it within the generated data stack. In the best-case scenario, we wouldn't update the generated data. However, we would improve the engine to generate or fix the problem generally for all destinations, not just one specific implementation.
The Need for Open Standards and Interoperability
Open standards can improve the lives of data engineers 🙂. In the best case, we would have them in place from the beginning, but each new technology or way of working goes through many lifecycles, finding the best approaches and solutions. This is a normal part of the game. We can only arrive at the perfect solution by trying.
But now, with data engineering existing for a long period, more data standards have been established. For example, standards around data modeling, including which architecture to use and when, and which Data Modeling Techniques. We have standardized on a few cloud providers (3-4) and have also standardized on runtime with Kubernetes running everywhere.
We standardize object storage with the S3 interface being the open standard; even none AWS tools like MinIO, Zenko, and many others implement S3 APIs. The same happened with data lake file formats, with Apache Parquet being the standard, besides exceptional use cases with schema use cases with Avro, Protobuf, and, of course, CSVs, JSON for quickly exporting and importing data.
The same happens with the open table formats, where we see a race and consolidation with the two biggest Delta Lake and Apache Iceberg by acquiring Tabular, the company behind Iceberg by Databricks (behind Delta Lake). Apache Hudi also maintains XTable to transform from one format to another to avoid lock-in. I could go on and on.
Open standards form the foundation for openness and integration, decoupling the data stack, which is also crucial for creating a DDS engine. Instead of implementing 1000+ adapters, we only need a couple of 100s.
Openness is also key to creating an environment where trust and visibility flourish, mainly through open source. All the code is open, with no lock-in or proprietary format/engine. If you want to go back, it started from the very beginning. Open source had its roots shortly before the announcement of Netscape, and it got mainstream with the recognition of Linux. Today, open source is the key to openness.
Examples of Open Standards at Work
Also, people can work together. It's a little with the data lakehouse we've seen. This is built on top of open source. There is less integration than a traditional data warehouse, but it is easier to exchange a tool, access your data, and be more open. And, you can still add proprietary functions and tools on top, such as Databricks has done with Photon Engine and some machine learning capabilities. Snowflake did similar things when integrating Apache Iceberg, Snowplow, and another open-source tool to open the platform.
Dremio is another example of a company that has built a business model on top of Apache Iceberg and Apache Arrow, thereby eliminating vendor lock-in for larger organizations.
Open standards are what we need as engineers.
The Beauty of Open-Source
The beauty of open-source is that the more you share, the more feedback, contributions, and, most importantly, trust a product receives. It allows fast iteration cycles with multiple participants who can contribute, and everything is version-controlled and transparent—which makes it best of breed for security reasons to find and fix them fast. Usually, open sourcing improves a product, as contributions from the community cannot be compared to those made by a small team of in-house engineers.
Coming Soon: A Full Implementation
The exploration of building a declarative data stack engine has highlighted both the promise and challenges of this approach. While DWA tools provide an excellent mental model for making everything code-first, creating a responsive developer experience with quick feedback loops is the main challenge. Working with generated code versus maintaining configs with a templated approach leads to tension that needs to be balanced.
The path forward likely involves focusing on open standards and modular adapters rather than building a monolithic engine. This allows different implementations to coexist while maintaining consistent interfaces across tools. If you want to follow along with this exploration, check out the declarative-data-stack-engine repository, where I'm experimenting with various approaches, including using SDF for ingestion/transformation and Rill for serving. While the current implementation is still a work in progress, it provides a starting point for further discussing and evolving these ideas. If it sparked any ideas or you disagree with said points, I'd love to hear your opinions on building or designing a better version of the declarative data stack and its engine.
The next article will explore practical implementations deeper, exploring how to build real-world systems using these principles and examining specific use cases like analyzing Bluesky data. We'll see how declarative approaches can simplify complex data engineering tasks while maintaining the flexibility and power needed for modern data stacks.
Appendix
- For illustration purposes it's just as part of the code, but imagine this being in a separate file
- And thanks to the feedback on socials if you replied to my earlier posts
- Special thanks go to the founder, Matthew Kosovec, who has valuable insights on this topic and is not shy about sharing them. Check out his YouTube channel or explore the DataForge repository.

.svg)
.jpg)
.png)

Ready for faster dashboards?
Try for free today.